from toolkit import H
from sklearn import datasets
Windows 10
Python 3.7.3 @ MSC v.1915 64 bit (AMD64)
Latest build date 2020.11.07
sklearn version: 0.23.1
数据集
sklearn包自带一些玩具数据集,还具有一些人工数据生成器。主要接口如下:
-
datasets.load_*():获取小规模数据集,数据已经包含在datasets里面。load_*函数有一个通用参数return_X_y,默认值为return_X_y=False,这会返回一个sklearn.utils.Bunch对象。如果return_X_y=True,则仅返回tuple:(data,target)。 -
datasets.fetch_*():获取大规模数据集,需要从网络上下载。函数的第一个参数是data_home,表示数据集下载的目录,默认是~/scikit_learn_data/。~表示计算机用户路径,例如'C:\Users\UserName'。要修改默认目录,可以修改环境变量SCIKIT_LEARN_DATA。 -
datasets.make_*():本地生成数据集。
datasets.get_data_home() # 获取数据集目录
datasets.clear_data_home(data_home=None) # 删除所有下载数据
load*和fetch*函数返回的数据类型是datasets.base.Bunch,本质上是一个dict。可像dict一样,通过key访问value,也可以通过对象属性方式访问,主要包含以下属性:
-
data:特征数据数据(样本集),是 $\text{n_samples} \times \text{n_features}$ 的二维
numpy.ndarray数组 -
target:标签数组,是
n_samples的一维numpy.ndarray -
DESCR:数据描述
-
feature_names:特征名
-
target_names:标签名
loaders:加载器——获取小数据集
小数据集在sklearn里面的API统一为load_,The dataset loaders可以加载小型标准数据。小数据集是封装在sklearn里面的。
一共有12个小数据集。分别如下:
-
波士顿房价数据集
load_boston(return_X_y),回归 -
乳腺癌数据集
load_breast_cancer(return_X_y),分类 -
糖尿病数据集
load_diabetes(return_X_y),回归 -
数字数据集
load_digits(n_class, return_X_y),分类 -
鸢尾花数据集
load_iris(return_X_y),分类 -
葡萄酒数据集
load_wine(return_X_y),分类 -
···
这些数据集可用于快速实现scikit-learn中的各种算法。但是这些数据集太小,并不能代表现实世界的机器学习任务。
'''
用于分类的iris数据
'''
iris = datasets.load_iris(return_X_y=True) # (data,target) 的二维tuple
type(iris)
iris = datasets.load_iris(return_X_y=False)
type(iris)
iris.data # 样本数据
iris["data"]
iris.target # label 数据
iris.DESCR # 数据描述
iris.feature_names # 样本特征名(变量名)
iris.target_names # label 名
fetchers:提取器——获取大数据集
# 加载20个新闻组数据集中的文件名和数据
datasets.fetch_20newsgroups(data_home=None, subset='train', categories=None,
shuffle=True, random_state=42, remove=(),
download_if_missing=True)
data_home: 指定数据集的缓存文件夹。默认值:None,表示存储在〜/ scikit_learn_data文件夹中。
subset: train或者test,all,可选,分别对应训练集、测试集、两者。
categories: 无或字符串或Unicode的集合,默认值为None,加载所有类别。如果不是无,要加载的类别名称列表(忽略其他类别)
shuffle: 是否对数据进行洗牌。
random_state: numpy随机数生成器或种子整数。
download_if_missing: 可选,默认为True,如果False,如果数据不在本地可用而不是尝试从源站点下载数据,则引发IOError。
一共有11个小数据集。分别如下:
-
20组新闻数据
fetch_20newsgroups(),分类 -
20组向量化的新闻数据
fetch_20newsgroups_vectorized(),分类 -
加利福尼亚住房数据集
fetch_california_housing(),回归 -
fetch_covtype(),分类 -
fetch_kddcup99(),分类 -
fetch_lfw_pairs(),分类 -
fetch_lfw_people(),分类 -
fetch_olivetti_faces(), -
fetch_openml(), -
fetch_rcvl(),分类 -
fetch_species_distributions(),分类
Samples generators:样本生成器
多类别分类
make_classification:生成随机的$n$分类数据。
datasets.make_classification(n_samples=100, n_features=20,
n_informative=2, n_redundant=2,
n_repeated=0, n_classes=2,
n_clusters_per_class=2, weights=None,
flip_y=0.01, class_sep=1.0,
hypercube=True, shift=0.0, scale=1.0,
shuffle=True, random_state=None)
n_samples: int,optional(default = 100),样本数量。
n_features: int,可选(默认= 20),特征总数。n_features必须大于等于n_repeated+n_repeated+n_informative。
n_repeated: int,重复的特征数量。
n_redundant: int,与其他特征线性相关的特征数量 (冗余特征)。
n_informative: int,带有信息的特征的数量。n_clusters_per_class must be smaller or equal 2 ** n_informative。
n_classes: int,可选(default = 2),类(或标签)的分类问题的数量。
weights: 每个类的权重,用于分配样本点。
lip_y: 随机分配类别的样本比例。较大的值会在标签中引入噪音,并使分类任务更加困难。 class_sep: 超立方体大小乘以的因子。较大的值分散了群集/类,使分类任务更加容易。
random_state: int,RandomState实例或无,可选(默认=无)如果int,random_state是随机数生成器使用的种子如果RandomState的实例,random_state是随机数生成器如果没有,随机数生成器所使用的RandomState实例np.random。
return: X特征数据集;y目标分类值。
多标签分类
datasets.make_multilabel_classification(n_samples=100, n_features=20,
n_classes=5, n_labels=2,
length=50,
allow_unlabeled=True,
sparse=False,
return_indicator='dense',
return_distributions=False,
random_state=None)
回归
make_regression:生成回归数据。
# 生成用于回归的数据集
datasets.make_regression(n_samples=100, n_features=100, n_informative=10,
n_targets=1, bias=0.0, effective_rank=None,
tail_strength=0.5, noise=0.0, shuffle=True,
coef=False, random_state=None)
n_samples: int,optional(default = 100),样本数量。
n_features: int,optional(default = 100),特征数量。
coef: boolean,optional(default = False),如果为True,则返回底层线性模型的系数。
random_state: int,RandomState实例或无,可选(默认=无)如果int,random_state是随机数生成器使用的种子如果RandomState的实例,random_state是随机数生成器如果没有,随机数生成器所使用的RandomState实例np.random。
return: X特征数据集;y目标分类值。
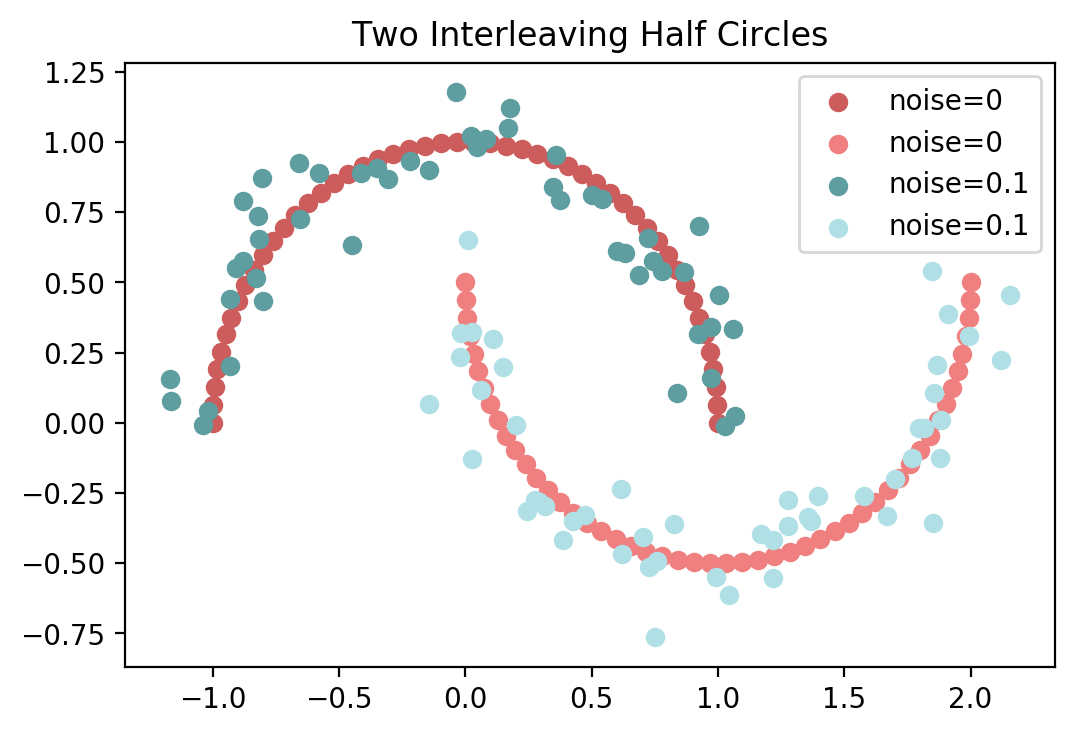
两个交错的半圆
make_moons生成的数据可用于分类或聚类任务。
datasets.make_moons(n_samples=100, shuffle=True, noise=None,
random_state=None)
noise:加到数据中的高斯噪声的标准差。
X, y = datasets.make_moons(n_samples=100, random_state=1)
X1, y1 = datasets.make_moons(n_samples=100, noise=0.1, random_state=1)
plt.scatter(X[y==0][:,0], X[y==0][:,1], c="#CD5C5C",label="noise=0")
plt.scatter(X[y==1][:,0], X[y==1][:,1], c="#F08080",label="noise=0")
plt.scatter(X1[y1==0][:,0], X1[y1==0][:,1], c="#5F9EA0",label="noise=0.1")
plt.scatter(X1[y1==1][:,0], X1[y1==1][:,1], c="#B0E0E6",label="noise=0.1")
plt.title("two interleaving half circles".title())
plt.legend()
plt.show()
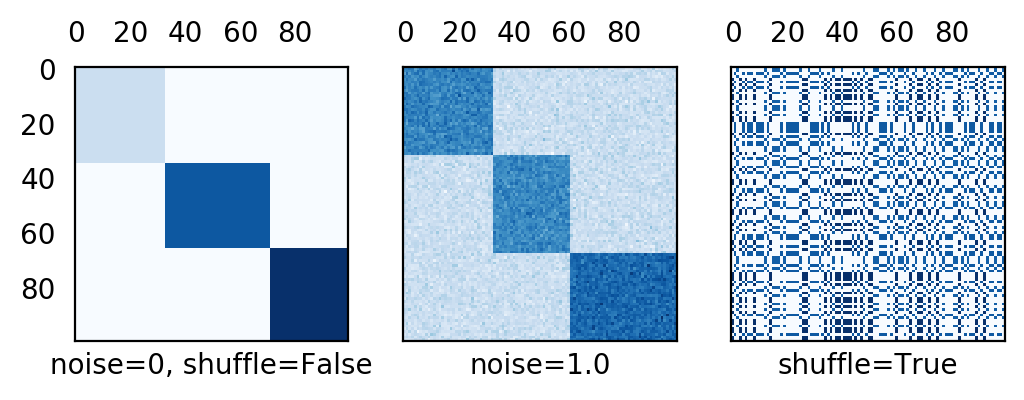
常量对角块矩阵
make_biclusters生成具有constant block对角线结构的矩阵,可用于双聚类。
datasets.make_biclusters(shape, n_clusters, noise=0.0, minval=10,
maxval=100, shuffle=True, random_state=None)
params = dict(shape=(100, 100), n_clusters=3,
minval=1, maxval=10, noise=0,
random_state=None, shuffle=False)
X, row_idx, col_idx = datasets.make_biclusters(**params)
X1, *_ = datasets.make_biclusters(
**{k: v if k != "noise" else 1 for k, v in params.items()})
X2, *_ = datasets.make_biclusters(
**{k: v if k != "shuffle" else True for k, v in params.items()})
fig, axs = plt.subplots(1, 3, sharex=True, sharey=True)
data = [X, X1, X2]
titles = ["noise=0, shuffle=False", "noise=1.0", "shuffle=True"]
for i, data, title in zip(range(3), [X, X1, X2], titles):
axs[i].matshow(data, cmap=plt.cm.Blues)
axs[i].set_xlabel(title)
axs[i].xaxis.set_ticks_position('none')
axs[i].yaxis.set_ticks_position('none')
plt.show()
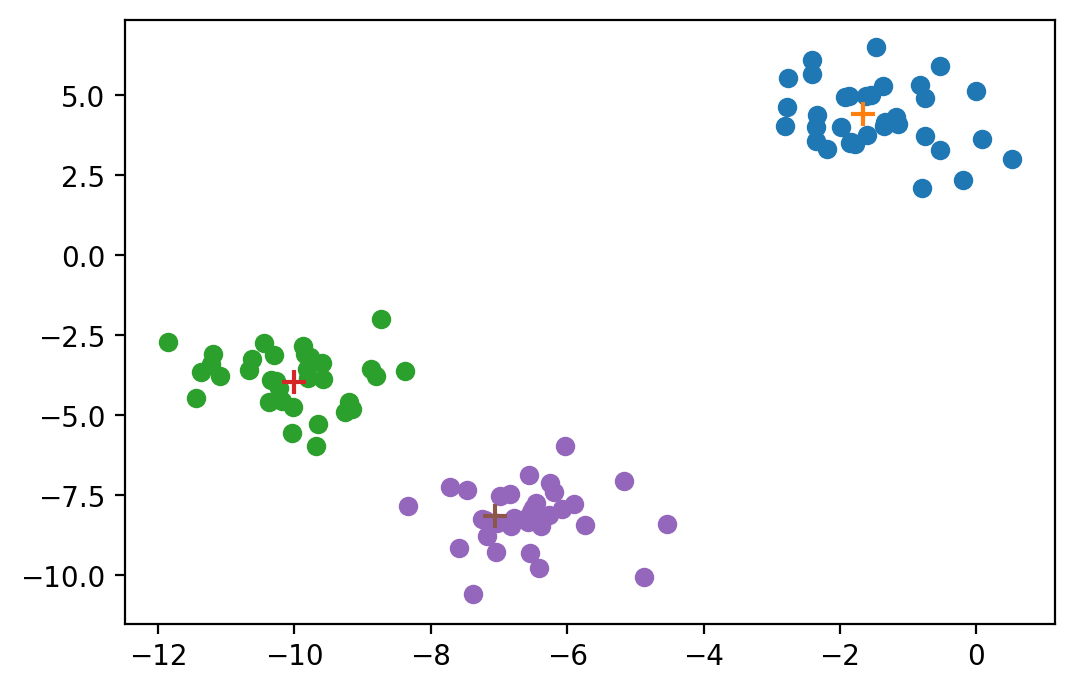
各向同性的高斯点
datasets.make_blobs(n_samples=100, n_features=2, centers=None,
cluster_std=1.0, center_box=(-10.0, 10.0),
shuffle=True, random_state=None, return_centers=False)
X, label, centers = datasets.make_blobs(cluster_std=1, return_centers=True,
random_state=1)
for i in set(label):
plt.scatter(X[label==i][:,0], X[label==i][:,1])
plt.scatter(centers[i,0], centers[i,1], s=80, marker="+")
plt.show()
棋盘格结构的矩阵
make_checkerboard生成具有棋盘格结构的矩阵,可用于双聚类。
datasets.make_checkerboard(shape, n_clusters, noise=0.0, minval=10,
maxval=100, shuffle=True, random_state=None)
# datasets.make_checkerboard
X, row_idx, col_idx = datasets.make_checkerboard(shape=(100, 100), n_clusters=3,
minval=0, maxval=20, noise=0.1,
shuffle=False, random_state=1)
plt.matshow(X, cmap=plt.cm.Blues)
plt.show()

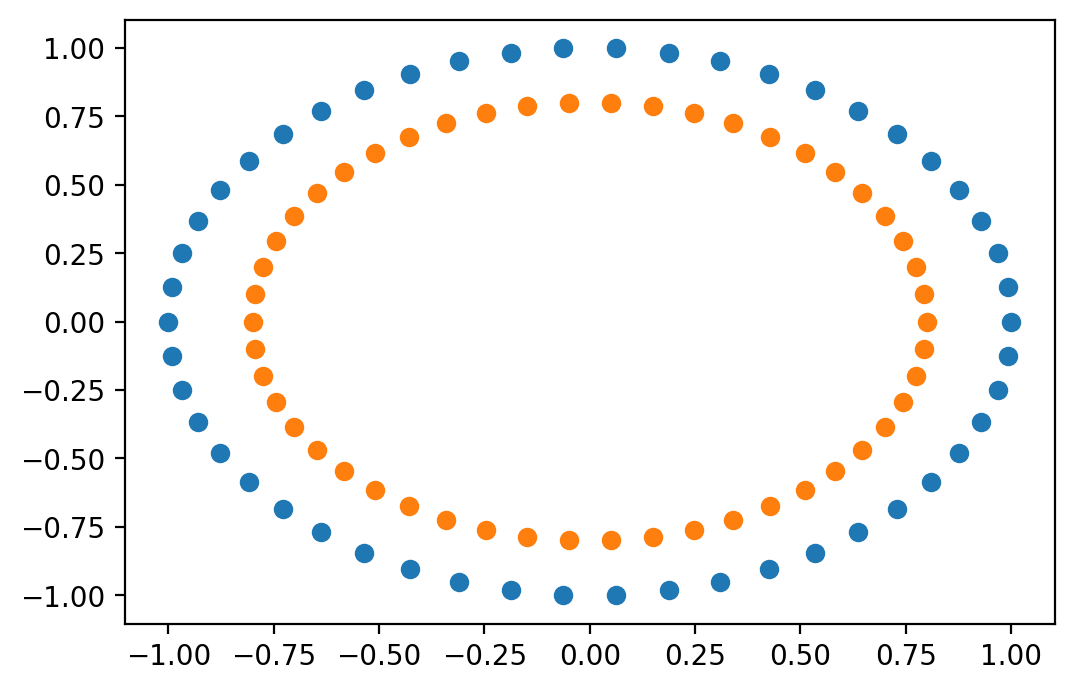
包含小圆的大圆
用于聚类和分类。
datasets.make_circles(n_samples=100, shuffle=True, noise=None,
random_state=None, factor=0.8)
X, y = datasets.make_circles()
outer, inner = y==0, y==1
plt.scatter(X[outer][:,0], X[outer][:,1])
plt.scatter(X[inner][:,0], X[inner][:,1])
plt.show()
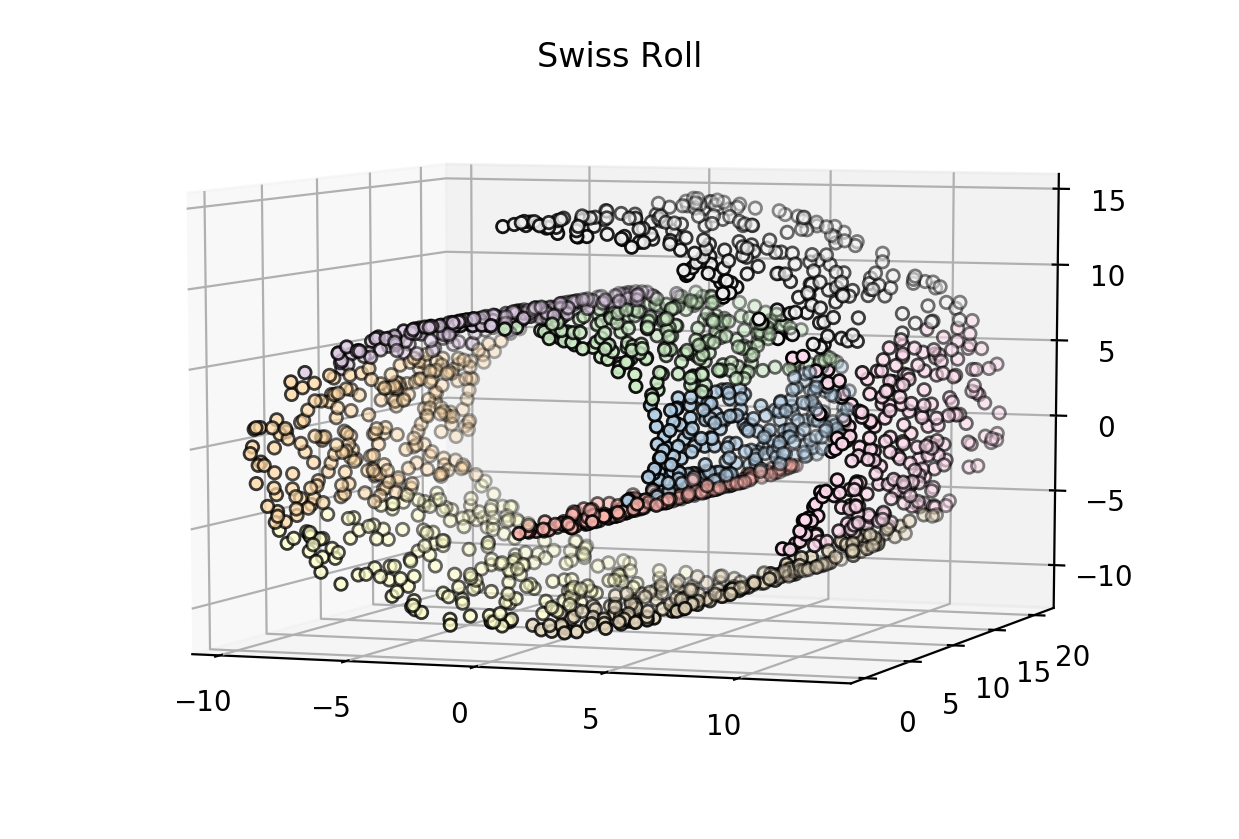
瑞士卷
datasets.make_swiss_roll(n_samples=100, noise=0.0, random_state=None)
import mpl_toolkits.mplot3d.axes3d as p3
X, y = datasets.make_swiss_roll(2000)
fig = plt.figure()
ax = p3.Axes3D(fig)
ax.view_init(7, -70)
ax.scatter(X[:, 0], X[:, 1], X[:, 2],
# color="#DAA520",
c = y,
cmap = plt.cm.Pastel1,
s=20, edgecolor='k')
plt.title("Swiss Roll")
plt.show()
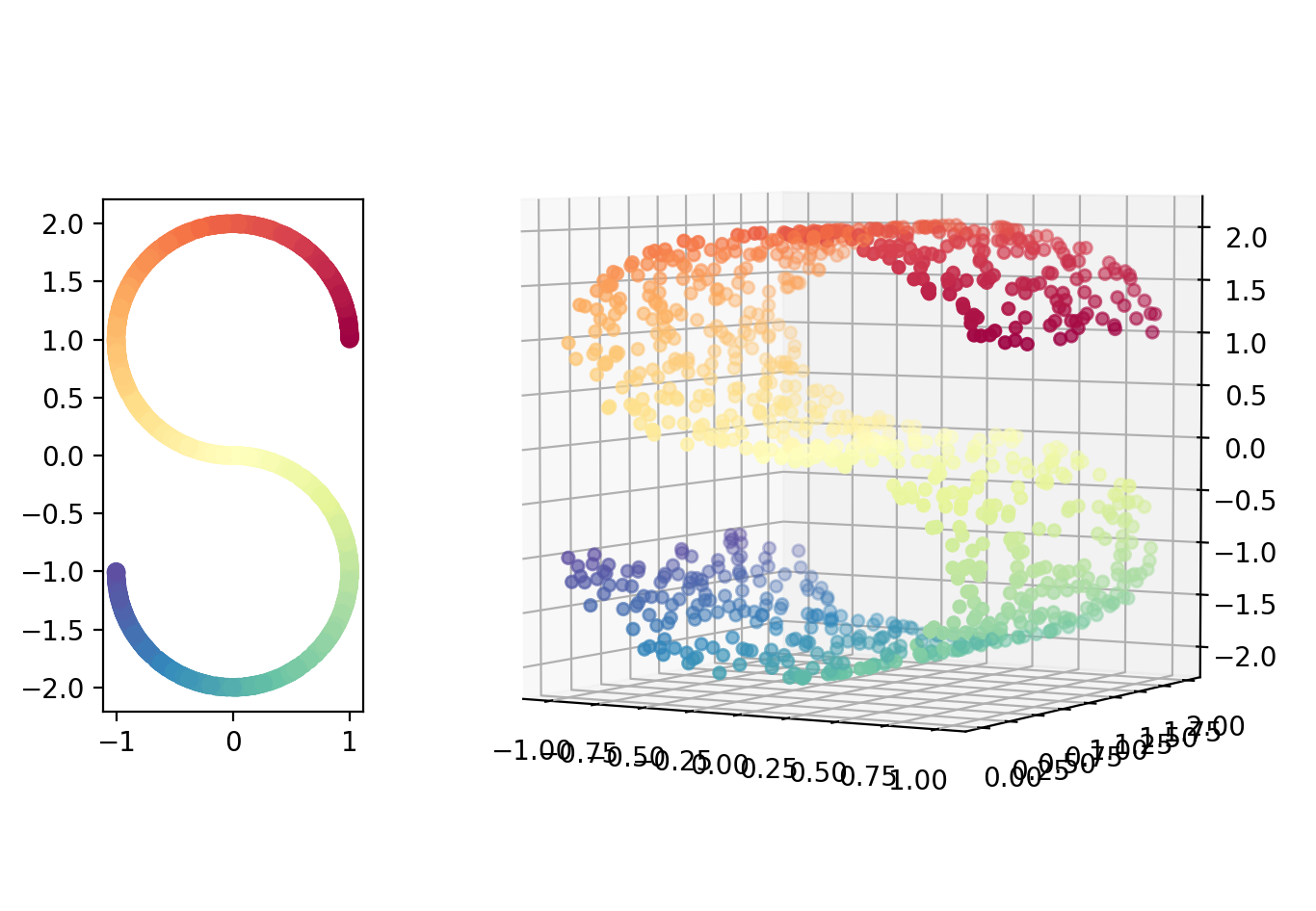
曲面
datasets.make_s_curve(n_samples=100, noise=0.0, random_state=None)
X, color = datasets.make_s_curve(1000, random_state=0)
fig = plt.figure(figsize=(8, 6))
# fig.suptitle("S curve", fontsize=25)
ax = plt.subplot2grid((5,4), (1,0), rowspan=3, colspan=1)
ax.scatter(X[:, 0], X[:, 2], c=color, cmap=plt.cm.Spectral)
# ax.xaxis.set_major_formatter(NullFormatter())
# ax.yaxis.set_major_formatter(NullFormatter())
# Add 3d scatter plot
ax = plt.subplot2grid((5,4), (0,1), rowspan=5, colspan=3, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=color, cmap=plt.cm.Spectral)
ax.view_init(4, -60)
plt.show()
随机对称正定矩阵
datasets.make_spd_matrix(n_dim, random_state=None)
X = datasets.make_spd_matrix(10, random_state=1)
plt.matshow(X, cmap=plt.cm.Blues)
plt.show()

随机对称正定稀疏矩阵
datasets.make_spd_matrix(n_dim, random_state=None)
X = datasets.make_sparse_spd_matrix(10, random_state=1)
plt.matshow(X, cmap=plt.cm.Blues)
plt.show()
