9.5.选择数据进阶
from toolkit import H
import numpy as np
import pandas as pd
import pprint
Windows 10
Python 3.8.8 @ MSC v.1928 64 bit (AMD64)
Latest build date 2021.04.18
pandas version: 1.2.2
numpy version: 1.20.1
创建索引和示例数据
def mklbl(prefix, n):
return ['%s%s' % (prefix, i) for i in range(n)]
miindex = pd.MultiIndex.from_product([mklbl('A', 4),
mklbl('B', 2),
mklbl('C', 4),
mklbl('D', 2)])
micolumns = pd.MultiIndex.from_tuples([('a', 'foo'),
('a', 'bar'),
('b', 'foo'),
('b', 'bah')],
names=['lvl0', 'lvl1'])
print(miindex, '\n')
print(micolumns, '\n')
MultiIndex([('A0', 'B0', 'C0', 'D0'),
('A0', 'B0', 'C0', 'D1'),
('A0', 'B0', 'C1', 'D0'),
('A0', 'B0', 'C1', 'D1'),
('A0', 'B0', 'C2', 'D0'),
('A0', 'B0', 'C2', 'D1'),
('A0', 'B0', 'C3', 'D0'),
('A0', 'B0', 'C3', 'D1'),
('A0', 'B1', 'C0', 'D0'),
('A0', 'B1', 'C0', 'D1'),
('A0', 'B1', 'C1', 'D0'),
('A0', 'B1', 'C1', 'D1'),
('A0', 'B1', 'C2', 'D0'),
('A0', 'B1', 'C2', 'D1'),
('A0', 'B1', 'C3', 'D0'),
('A0', 'B1', 'C3', 'D1'),
('A1', 'B0', 'C0', 'D0'),
('A1', 'B0', 'C0', 'D1'),
('A1', 'B0', 'C1', 'D0'),
('A1', 'B0', 'C1', 'D1'),
('A1', 'B0', 'C2', 'D0'),
('A1', 'B0', 'C2', 'D1'),
('A1', 'B0', 'C3', 'D0'),
('A1', 'B0', 'C3', 'D1'),
('A1', 'B1', 'C0', 'D0'),
('A1', 'B1', 'C0', 'D1'),
('A1', 'B1', 'C1', 'D0'),
('A1', 'B1', 'C1', 'D1'),
('A1', 'B1', 'C2', 'D0'),
('A1', 'B1', 'C2', 'D1'),
('A1', 'B1', 'C3', 'D0'),
('A1', 'B1', 'C3', 'D1'),
('A2', 'B0', 'C0', 'D0'),
('A2', 'B0', 'C0', 'D1'),
('A2', 'B0', 'C1', 'D0'),
('A2', 'B0', 'C1', 'D1'),
('A2', 'B0', 'C2', 'D0'),
('A2', 'B0', 'C2', 'D1'),
('A2', 'B0', 'C3', 'D0'),
('A2', 'B0', 'C3', 'D1'),
('A2', 'B1', 'C0', 'D0'),
('A2', 'B1', 'C0', 'D1'),
('A2', 'B1', 'C1', 'D0'),
('A2', 'B1', 'C1', 'D1'),
('A2', 'B1', 'C2', 'D0'),
('A2', 'B1', 'C2', 'D1'),
('A2', 'B1', 'C3', 'D0'),
('A2', 'B1', 'C3', 'D1'),
('A3', 'B0', 'C0', 'D0'),
('A3', 'B0', 'C0', 'D1'),
('A3', 'B0', 'C1', 'D0'),
('A3', 'B0', 'C1', 'D1'),
('A3', 'B0', 'C2', 'D0'),
('A3', 'B0', 'C2', 'D1'),
('A3', 'B0', 'C3', 'D0'),
('A3', 'B0', 'C3', 'D1'),
('A3', 'B1', 'C0', 'D0'),
('A3', 'B1', 'C0', 'D1'),
('A3', 'B1', 'C1', 'D0'),
('A3', 'B1', 'C1', 'D1'),
('A3', 'B1', 'C2', 'D0'),
('A3', 'B1', 'C2', 'D1'),
('A3', 'B1', 'C3', 'D0'),
('A3', 'B1', 'C3', 'D1')],
)
MultiIndex([('a', 'foo'),
('a', 'bar'),
('b', 'foo'),
('b', 'bah')],
names=['lvl0', 'lvl1'])
# Create DataFrame
dfmi = pd.DataFrame(np.arange(len(miindex) * len(micolumns)).
reshape((len(miindex), len(micolumns))),
index=miindex,
columns=micolumns).sort_index().sort_index(axis=1)
print(dfmi)
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 9 8 11 10
D1 13 12 15 14
C2 D0 17 16 19 18
... ... ... ... ...
A3 B1 C1 D1 237 236 239 238
C2 D0 241 240 243 242
D1 245 244 247 246
C3 D0 249 248 251 250
D1 253 252 255 254
[64 rows x 4 columns]
只有标签值索引具有多层级结构,即整数值索引没有多级结构,iloc/iat不支持多级索引。多级索引的使用让索引语法变得复杂,但总的来说,其索引种类可以分为如下几种:
- 标量:单个标签元组:
- 省略靠后层级:
("A0", "B1") - 包含完整层级:
("A0", "B1", "C1", "D0")
- 省略靠后层级:
-
序列
- 非重复的第一层级标签序列:
["A0", "A1", "A2"]np.array(["A0", "A1", "A2"])
- 完整层级的标签元组序列:
[("A0", "B1", "C1", "D0"), ("A0", "B0", "C0", "D1")][["A0", "B1", "C1", "D0"], ["A0", "B0", "C0", "D1"]][np.array(["A0", "B1", "C1", "D0"]), np.array(["A0", "B0", "C0", "D1"])]
- 嵌套在单个标签元组内的单层级标签序列:
("A0", ["B0", "B1"], ["C0", "C1"])
- 非重复的第一层级标签序列:
-
切片
同一轴的多级索使用运算符()括起来,这表示一个元组。
dfmi.loc[("A0", "B1", "C1")] # 省略第四层索引
lvl0 a b
lvl1 bar foo bah foo
D0 41 40 43 42
D1 45 44 47 46
实际上,loc默认选择行,可以省略列索引,而索引运算符[]只能选择行或列,因此,如果只使用“单个标签元组”,则loc/[]可以省略括号();若列索引不省略,loc的多级行索引不能省略括号():
print(dfmi.loc["A0", "B1", "C1"])
print()
try:
dfmi.loc["A0", ["B0", "B1"], ["C0"], "a"]
except KeyError as e:
print(f"KeyError: {e}")
lvl0 a b
lvl1 bar foo bah foo
D0 41 40 43 42
D1 45 44 47 46
KeyError: 'a'
at用于选择标量,虽然其返回的不一定是标量,但必须使用完整的多级索引:
dfmi.at[("A0", "B1", "C0", "D0"), ("a", "foo")]
32
使用“单个标签元组”时,loc/[]只能省略靠后层级的索引,不能省略前面层级的索引,例如下面前 4 行代码都是错误的:
dfmi.loc[, "B1", "C1"] # SyntaxError
dfmi.loc[(:, "B1", "C1")] # SyntaxError
dfmi.loc["B1", "C1"] # KeyError: 'B1'
dfmi["foo"] # KeyError: 'foo'
dfmi.loc[slice(None), "B1", "C1"] # √
dfmi["a"] # √
对于loc,如果“单个标签元组”内嵌序列索引,且省略列索引,在如下特殊情况中,不能省略括号():
# Is actually interpreted as dfmi.loc["A0", ["B0", "B1"]]
try:
dfmi.loc[("A0", ["B0", "B1"])]
except KeyError as e:
print(e)
# The correct syntax is as follows
print(dfmi.loc[("A0", ["B0", "B1"]), ])
# If the used index level more than 2, can omit `()`
print(dfmi.loc["A0", ["B0", "B1"], ["C0"]])
"['B0' 'B1'] not in index"
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 9 8 11 10
D1 13 12 15 14
C2 D0 17 16 19 18
D1 21 20 23 22
C3 D0 25 24 27 26
D1 29 28 31 30
B1 C0 D0 33 32 35 34
D1 37 36 39 38
C1 D0 41 40 43 42
D1 45 44 47 46
C2 D0 49 48 51 50
D1 53 52 55 54
C3 D0 57 56 59 58
D1 61 60 63 62
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
B1 C0 D0 33 32 35 34
D1 37 36 39 38
如果“序列索引”非嵌套在“单个标签元组”内,其元素要么是 同一层级且非重复的标签标量,要么是完整的多级索引。
# Label scalar
dfmi.loc[np.array(["A0", "B1"])] # KeyError: "['B1'] not in index"
dfmi[np.array(["a", "foo"])] # KeyError: "['foo'] not in index"
dfmi.loc[["A0", "A1"]] # √
dfmi[["a", "b"]] # √
在“序列索引”中使用层级索引时,完整的层级索引可以包裹在序列()/[]/array之中。
# Full multi-level index
dfmi[[ ["a", "foo"], ["a", "bar"] ]] # √
dfmi[[ np.array(["a", "foo"]), np.array(["a", "bar"]) ]] # √
dfmi.loc[[ ["A0", "B0", "C0", "D0"] ]] # √
dfmi.loc[[ ("A0", "B0", "C0", "D0") ]] # √
try:
dfmi.loc[[ ("A0", "B0", "C0") ]]
except ValueError as e:
print(e)
operands could not be broadcast together with shapes (1,3) (4,) (1,3)
使用切片
slice
dfmi.loc[(slice('A1', 'A3'), slice(None), ['C1', 'C3']), :]
dfmi.loc['A1', (slice(None), 'foo')]
lvl0 a b
lvl1 foo foo
B0 C0 D0 64 66
D1 68 70
C1 D0 72 74
D1 76 78
C2 D0 80 82
D1 84 86
C3 D0 88 90
D1 92 94
B1 C0 D0 96 98
D1 100 102
C1 D0 104 106
D1 108 110
C2 D0 112 114
D1 116 118
C3 D0 120 122
D1 124 126
IndexSlice
idx = pd.IndexSlice
dfmi.loc[idx[:, :, ['C1', 'C3']], idx[:, 'foo']]
lvl0 a b
lvl1 foo foo
A0 B0 C1 D0 8 10
D1 12 14
C3 D0 24 26
D1 28 30
B1 C1 D0 40 42
D1 44 46
C3 D0 56 58
D1 60 62
A1 B0 C1 D0 72 74
D1 76 78
C3 D0 88 90
D1 92 94
B1 C1 D0 104 106
D1 108 110
C3 D0 120 122
D1 124 126
A2 B0 C1 D0 136 138
D1 140 142
C3 D0 152 154
D1 156 158
B1 C1 D0 168 170
D1 172 174
C3 D0 184 186
D1 188 190
A3 B0 C1 D0 200 202
D1 204 206
C3 D0 216 218
D1 220 222
B1 C1 D0 232 234
D1 236 238
C3 D0 248 250
D1 252 254
给 loc或iloc 指定轴参数
loc默认对行进行索引,但也可以对其指定axis参数,指定需要索引的轴。当存在多级索引,或者想显式指定需要索引的轴时比较有用。
print(dfmi.loc(axis=0)[:, :, ['C1', 'C3']])
print(dfmi.loc(axis=1)['a'])
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C1 D0 9 8 11 10
D1 13 12 15 14
C3 D0 25 24 27 26
D1 29 28 31 30
B1 C1 D0 41 40 43 42
D1 45 44 47 46
C3 D0 57 56 59 58
D1 61 60 63 62
A1 B0 C1 D0 73 72 75 74
D1 77 76 79 78
C3 D0 89 88 91 90
D1 93 92 95 94
B1 C1 D0 105 104 107 106
D1 109 108 111 110
C3 D0 121 120 123 122
D1 125 124 127 126
A2 B0 C1 D0 137 136 139 138
D1 141 140 143 142
C3 D0 153 152 155 154
D1 157 156 159 158
B1 C1 D0 169 168 171 170
D1 173 172 175 174
C3 D0 185 184 187 186
D1 189 188 191 190
A3 B0 C1 D0 201 200 203 202
D1 205 204 207 206
C3 D0 217 216 219 218
D1 221 220 223 222
B1 C1 D0 233 232 235 234
D1 237 236 239 238
C3 D0 249 248 251 250
D1 253 252 255 254
lvl1 bar foo
A0 B0 C0 D0 1 0
D1 5 4
C1 D0 9 8
D1 13 12
C2 D0 17 16
... ... ...
A3 B1 C1 D1 237 236
C2 D0 241 240
D1 245 244
C3 D0 249 248
D1 253 252
[64 rows x 2 columns]
布尔索引
布尔索引经常会用到,例如想找出DataFrame中大于、小于或等于某值的所有元素:
mask = dfmi[('a', 'foo')] > 200
dfmi.loc[idx[mask, :, ['C1', 'C3']], idx[:, 'foo']]
lvl0 a b
lvl1 foo foo
A3 B0 C1 D1 204 206
C3 D0 216 218
D1 220 222
B1 C1 D0 232 234
D1 236 238
C3 D0 248 250
D1 252 254
可以对布尔索引执行并、或、非运算,从而得到复杂的过滤条件
s = pd.Series(range(-3, 4))
print(s[(s < -1) | (s > 0.5)])
print(s[~((s < -1) | (s > 0.5))])
0 -3
1 -2
4 1
5 2
6 3
dtype: int64
2 -1
3 0
dtype: int64
使用列表推导式和map函数可产生更复杂的条件:
df2 = pd.DataFrame({'a': ['one', 'one', 'two', 'three', 'two', 'one', 'six'],
'b': ['x', 'y', 'y', 'x', 'y', 'x', 'x'],
'c': np.random.randn(7)})
# only want 'two' or 'three'
criterion = df2['a'].map(lambda x: x.startswith('t'))
print(df2[criterion])
# equivalent but slower
print(df2[[x.startswith('t') for x in df2['a']]])
# Multiple criteria
print(df2[criterion & (df2['b'] == 'x')])
a b c
2 two y 0.818708
3 three x 1.481461
4 two y 0.243370
a b c
2 two y 0.818708
3 three x 1.481461
4 two y 0.243370
a b c
3 three x 1.481461
where/mask方法
布尔索引返回的结果通常是数据的子集:
ser = pd.Series([2, 2, 3])
print(ser[ser > 2])
2 3
dtype: int64
现在布尔索引在DataFrame上返回的结果和原始数据具有相同的形状:
df = pd.DataFrame({"a": [4, 2, 3],
"b": [4, 3, 1]})
print(df[df >= 4])
a b
0 4.0 4.0
1 NaN NaN
2 NaN NaN
这是通过where方法实现的,实际上等效于df.where[df >= 4]。为了确保布尔索引的输出与原始数据具有相同的形状,可以使用where方法:
ser.where(ser > 2)
0 NaN
1 NaN
2 3.0
dtype: float64
where方法还有几个可选参数:
df.where(cond, other=nan, inplace=False, axis=None, level=None,
errors='raise', try_cast=False)
other:cond为False的条目将被替换为other。如果other是可调用的,则在DataFrame上对其进行计算,并应返回标量或DataFrame。可调用对象不得更改DataFrame(尽管pandas不会对其进行检查)。
mask方法是的where的逆布尔运算,它和where方法具有相同的参数。
ser.mask(ser > 2)
0 2.0
1 2.0
2 NaN
dtype: float64
isin方法
Series、DataFrame、Index都有.isin方法。.isin方法接受数组或字典作为参数。如果参数是一个数组,则isin返回与原始DataFrame形状相同的布尔DataFrame。
df = pd.DataFrame({'vals': [1, 2, 3, 4],
'ids': ['a', 'b', 'f', 'n'],
'ids2': ['a', 'n', 'c', 'n']})
values = ['a', 'b', 1, 3]
df.isin(values)
vals ids ids2
0 True True True
1 False True False
2 True False False
3 False False False
有时需要将某些值与某些列匹配。此时,则需要将dict作为.isin方法的参数。该字典的键为列标签,其值为要检查的元素列表。
values = {'ids': ['a', 'b'], 'vals': [1, 3]}
df.isin(values)
vals ids ids2
0 True True False
1 False True False
2 True False False
3 False False False
xs方法:选取横截面数据
pd.DataFrame.xs(self, key, axis=0, level=None, drop_level=True)
DataFrame 的xs()方法可以方便地在0轴或1轴的多级索引中的某一个层级进行数据的选取。xs方法实际上也可以作用与单层索引,但一般不会这样使用。与loc、iloc方法不同,xs方法只返回值,不能用于赋值。
df = dfmi.loc[("A0", "B0", ["C0", "C1"])]
df
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 9 8 11 10
D1 13 12 15 14
.xs方法默认axis=0:
df.xs('bar', level='lvl1', axis=1)
lvl0 a
A0 B0 C0 D0 1
D1 5
C1 D0 9
D1 13
df.xs(('a', 'bar'), level=('lvl0', 'lvl1'), axis=1)
lvl0 a
lvl1 bar
A0 B0 C0 D0 1
D1 5
C1 D0 9
D1 13
.xs方法默认drop_level=False:
df.xs('a', level='lvl0', axis=1, drop_level=False)
lvl0 a
lvl1 bar foo
A0 B0 C0 D0 1 0
D1 5 4
C1 D0 9 8
D1 13 12
df.xs('a', level='lvl0', axis=1, drop_level=True)
lvl1 bar foo
A0 B0 C0 D0 1 0
D1 5 4
C1 D0 9 8
D1 13 12
query方法:Query the columns with boolean expression
query方法允许DataFrame对象具有使用表达式选择列数据。query方法目前使用两种后端执行表达式:纯Python、numexpr。
df.query(expr, inplace=False, kwargs)
df = pd.DataFrame(np.random.rand(8, 3), columns=list('abc'))
print(df[(df['a'] < df['b']) & (df['b'] < df['c'])])
print(df.query('(a < b) & (b < c)'))
a b c
3 0.393407 0.755739 0.924355
7 0.126168 0.249316 0.434050
a b c
3 0.393407 0.755739 0.924355
7 0.126168 0.249316 0.434050
如果没有名称为a的列,则使用命名行索引:
df = pd.DataFrame(np.random.randint(4, size=(4, 2)), columns=list('bc'))
df.index.name = 'a'
print(df.query('a < b and b < c'))
Empty DataFrame
Columns: [b, c]
Index: []
如果行索引名称与列名重叠,则列名优先。如果您不想或无法命名行索引,则可以在查询表达式中使用"index":
df = pd.DataFrame(np.random.randint(4, size=(4, 2)), columns=list('bc'))
print(df.query('index < b < c'))
Empty DataFrame
Columns: [b, c]
Index: []
不管行索引是否被命名,都可以通过使用特殊标识符'index'在查询表达式中使用行索引。如果已经有一个名为'index'的列,那么也可以通过'ilevel_0'引用行索引,'ilevel_0'表示行索引的第0层级。但此时,您应该考虑将列重命名为不太模糊的名称。
MultiIndex中的query语法
如果行索引是MultiIndex的,你可以像使用列数据一样使用行索引。
level_0 = ['red', 'red', 'red', 'green', 'green',
'green', 'green', 'green', 'green', 'green']
level_1 = ['ham', 'ham', 'eggs', 'eggs', 'eggs',
'ham', 'ham', 'eggs', 'eggs', 'eggs']
index = pd.MultiIndex.from_tuples(tuple(zip(level_0, level_1)),
names=['color', 'food'])
df = pd.DataFrame(np.random.randn(10, 2), index=index)
print(df)
print(df.query('color == "red"'))
0 1
color food
red ham -0.112306 -0.397632
ham -0.549562 1.640438
eggs 0.872731 -1.482375
green eggs 0.859140 -0.526051
eggs -0.119190 0.916026
ham 1.895757 -1.374306
ham 0.040974 0.553177
eggs -0.585628 0.746558
eggs 1.313762 0.601611
eggs -1.233061 1.108511
0 1
color food
red ham -0.112306 -0.397632
ham -0.549562 1.640438
eggs 0.872731 -1.482375
如果MultiIndex的级别未命名,可以使用特殊名称引用它们:
df.index.names = [None, None]
print(df)
print(df.query('ilevel_0 == "red"'))
0 1
red ham -0.112306 -0.397632
ham -0.549562 1.640438
eggs 0.872731 -1.482375
green eggs 0.859140 -0.526051
eggs -0.119190 0.916026
ham 1.895757 -1.374306
ham 0.040974 0.553177
eggs -0.585628 0.746558
eggs 1.313762 0.601611
eggs -1.233061 1.108511
0 1
red ham -0.112306 -0.397632
ham -0.549562 1.640438
eggs 0.872731 -1.482375
query用例
当你拥有一组 DataFrame 对象,它们具有共同的列名子集(或索引层级名称),那么你可以将相同的查询传递给这两个 DataFrame ,而不必指定要查询的 DataFrame。
df = pd.DataFrame(np.random.rand(4, 3), columns=list('abc'))
df2 = pd.DataFrame(np.random.rand(6, 3), columns=df.columns)
expr = '0.0 <= a <= c <= 0.5'
map(lambda frame: frame.query(expr), [df, df2])
<map at 0x1dd96d666a0>
in\not in操作符
df = pd.DataFrame({'a': list('aabbccddeeff'), 'b': list('aaaabbbbcccc'),
'c': np.random.randint(5, size=12),
'd': np.random.randint(9, size=12)})
print(df)
df.query('a in b')
# How you'd do it in pure Python
df[df['a'].isin(df['b'])]
df.query('a not in b')
# pure Python
df[~df['a'].isin(df['b'])]
in\not in是在 vanilla Python 中计算的,因为 numexpr 没有此等效操作。通常,可以由 numexpr 执行的操作都是由 numexpr 计算的。例如,(b + c + d)由 numexpr 计算,然后在 Python 中计算 in 操作。
df.query('a in b + c + d')
与list共用的==操作符
使用==/!=与包含列名的列表进行比较,类似于in/not in。
df.query('b == ["a", "b", "c"]')
# pure Python
df[df['b'].isin(["a", "b", "c"])]
df.query('c == [1, 2]')
df.query('c != [1, 2]')
# using in/not in
df.query('[1, 2] in c')
df.query('[1, 2] not in c')
# pure Python
df[df['c'].isin([1, 2])]
布尔运算符
可以使用not或~运算符对布尔表达式求反。
df = pd.DataFrame(np.random.rand(3, 3), columns=list('abc'))
df['bools'] = np.random.rand(len(df)) > 0.5
print(df.query('~bools'))
print(df.query('not bools'))
print(df.query('not bools') == df[~df['bools']])
a b c bools
0 0.735107 0.618887 0.925549 False
1 0.688604 0.147859 0.128913 False
2 0.277222 0.312845 0.830238 False
a b c bools
0 0.735107 0.618887 0.925549 False
1 0.688604 0.147859 0.128913 False
2 0.277222 0.312845 0.830238 False
a b c bools
0 True True True True
1 True True True True
2 True True True True
当然,表达式也可以任意复杂:
# short query syntax
shorter = df.query('a < b < c and (not bools) or bools > 2')
# equivalent in pure Python
longer = df[(df['a'] < df['b'])
& (df['b'] < df['c'])
& (~df['bools'])
| (df['bools'] > 2)]
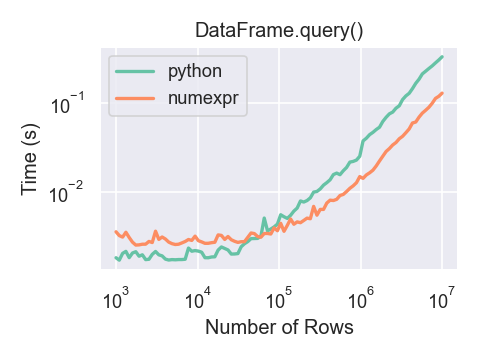
query的性能
如果 DataFrame 有大约 200,000 行以上,使用 numexpr 后端才能看到性能优势。

对于 big DataFrame,使用 numexpr 后端的DataFrame.query()比纯 Python 稍快一些。