8.3.内存布局
import numpy as np
import pprint
import copy
Windows 10
Python 3.8.8 @ MSC v.1928 64 bit (AMD64)
Latest build date 2021.03.02
numpy version: 1.20.1
ndarray 对象
NumPy 提供了一个 N 维数组对象 ndarray,它描述了同一类型的元素的集合。
ndarray 中所有元素都是同质的1:每个元素占用相同大小的内存块,并且所有内存块的解释方式完全相同。ndarray 内存块(数组中各元素)解释为特定数据类型所需的信息包含在 data-type 对象(dtype)之中。
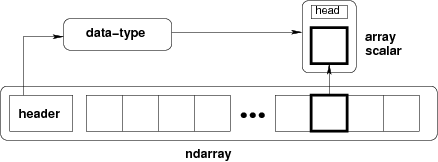
图中显示了用于描述数组中数据的三个基本对象之间的关系:
-
ndarray 本身
-
描述数组中单个固定大小元素的内存布局的 data-type 对象
-
访问数组的单个元素时返回的数组标量 Python 对象
Numpy 文档对 ndarray 的描述
ndarray 类的实例由一个连续的一维计算机内存块(由数组或其他对象拥有)和一个索引方案组合而成,该索引方案将N个整数分别映射到内存块中N个元素的位置。这种索引方案由数组的 shape 和 data type 定义,索引的范围受到 shape 的限制。
为什么需要 NumPy 数组
Python 的 list 或 tuple 序列可以储存同质的元素,也可以储存异构的元素,但如『数据类型』中所说,这种灵活性是有代价的。list 序列包含的元素都是完整的 Python 对象,这意味着每一个元素不仅包含了“原始的”值,还包含了各自的额外信息,例如:引用计数ob_refcnt、值的范围ob_size、值的类型ob_type等。额外信息带来了更多的开销,这在包含了许多元素的 Python 容器对象中尤其明显。在所有变量都具有相同类型的特殊情况下,这些信息大部分是冗余的,此时,将数据存储在固定类型的数组中更有效。
Python 列表和固定类型的 NumPy 数组的区别如下图所示:

在具体实现方面,数组实际上包含一个指向一个连续数据块的指针;而 Python 列表包含一个指向指针块的指针,每个指针又指向一个完整的 Python 对象。
列表的优点是灵活性,因为每个列表元素都是包含数据和类型信息的完整结构,所以列表可以填充任何所需类型的数据。固定类型的 NumPy 数组缺乏这种灵活性,但在存储和操作数据方面要高效得多。
Python 提供了几种不同的选择,用于在 高效的固定类型的数据缓冲区 中存储数据。例如,内置的array 模块(Python 3.3+)可用于创建统一类型的密集数组。
import array
L = list(range(10))
A = array.array('i', L)
A
array('i', [0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
这里的
'i'是一个类型代码,指示内容是整数。
但更有用的还是 NumPy 数组。虽然 Python 的 array 对象提供了基于数组数据的高效存储,但 NumPy 还提供了对数组数据的高效操作。
内存布局
ndarray 看上去似乎可以是多维的,但在内存中,ndarray 是一维储存的。有许多方案将N维数组以一维数组的形式储存在内存中。其中 Numpy 有两种储存方式:
-
元素按行顺序储存(C语言风格)
-
或者按列顺序储存(Fortran语言风格)

因此,如果要对一个 ndarray 以行为单位进行操作,最好以 C 的方式创建 ndarray;如果要对一个 ndarray 以列为单位进行操作,则用 Fortran 方式。

A = copy.deepcopy(np.arange(9, dtype=np.int16).reshape(3,3))
pprint.pprint(A)
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]], dtype=int16)
数组 A 与内存布局相关的属性如下:
| 属性 | A的属性值 | 描述 |
|---|---|---|
| A.dtype | dtype('int16') |
元素数据类型。A的每个元素是16bit大小的int型数据。 |
| A.ndim | 2 |
轴(维度)的个数。A有两个轴:0轴、1轴。 |
| A.shape | (3, 3) |
各个轴的大小。0轴有3个元素,1轴有3个元素。 |
| A.size | 9 |
数组的大小,有多少个元素。 |
| A.data | <memory address> |
指向数组的数据的存储区。 |
| A.itemsize | 2 |
一个元素的长度,以字节为单位。16bit等于2字节。 |
| A.nbytes | 18 |
数组元素占据的总字节数。 |
| A.base | None |
如果内存来自其他对象,则以此为基础对象。 |
| A.flags | 有关数组内存布局的信息。 | |
| A.strides | (6, 2) |
一个整数元组,每个元素保存着每个轴上相邻两个元素的地址差。 即当某个轴的下标增加1 时,数据存储区中的指针增加的字节数。 |
可以从不同的角度观察该 array:
shape[1]
(=3)
┌───────────┐
┌ ┌---┬---┬---┐ ┐
│ │ 0 │ 1 │ 2 │ │
│ ├---┼---┼---┤ │
shape[0] │ │ 3 │ 4 │ 5 │ │ len(Z)
(=3) │ ├---┼---┼---┤ │ (=3)
│ │ 6 │ 7 │ 8 │ │
└ └---┴---┴---┘ ┘
展开的 item layout
┌---┬---┬---┬---┬---┬---┬---┬---┬---┐
│ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ 8 │
└---┴---┴---┴---┴---┴---┴---┴---┴---┘
└─────────────────────────────────────┘
A.size
(=9)
内存布局(C顺序)
strides[1]
(=2)
┌---------------------┐
┌ ┌----------┬----------┐ ┐
│ p+00: │ 00000000 │ 00000000 │ │
│ ├----------┼----------┤ │
│ p+02: │ 00000000 │ 00000001 │ │ strides[0]
│ ├----------┼----------┤ │ (=2x3)
│ p+04 │ 00000000 │ 00000010 │ │
│ ├----------┼----------┤ ┘
│ p+06 │ 00000000 │ 00000011 │
│ ├----------┼----------┤
A.nbytes │ p+08: │ 00000000 │ 00000100 │
(=3x3x2) │ ├----------┼----------┤
│ p+10: │ 00000000 │ 00000101 │
│ ├----------┼----------┤
│ p+12: │ 00000000 │ 00000110 │
│ ├----------┼----------┤
│ p+14: │ 00000000 │ 00000111 │
│ ├----------┼----------┤
│ p+16: │ 00000000 │ 00001000 │
└ └----------┴----------┘
└---------------------┘
A.itemsize
A.dtype.itemsize
(=2)
如果我们现在取一A的切片,结果是A的基本数组的一个视图:
V = A[::2,::2]
这样的视图是由shape,dtype 和strides指定的,因为仅凭dtype和shape不能推断出strides:
如果我们现在取一A的切片,结果是A的基本数组的一个视图:
V = A[::2,::2]
这样的视图是由shape,dtype 和strides指定的,因为仅凭dtype和shape不能推断出strides:
Item layout
shape[1]
(=2)
┌-----------┐
┌ ┌---┬---┬---┐ ┐
│ │ 0 │ │ 2 │ │ ┌---┬---┐
│ ├---┼---┼---┤ │ | 0 │ 2 │
shape[0] │ │ │ │ │ │ len(A) --> ├---┼---┤
(=2) │ ├---┼---┼---┤ │ (=2) | 6 │ 8 │
│ │ 6 │ │ 8 │ │ └---┴---┘
└ └---┴---┴---┘ ┘
展开的item layout
┌---┬---┬---┬---┬---┬---┬---┬---┬---┐ ┌---┬---┬---┬---┐
│ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ 8 │ → │ 0 │ 2 │ 6 │ 8 │
└---┴---┴---┴---┴---┴---┴---┴---┴---┘ └---┴---┴---┴---┘
└-┬-┘ └-┬-┘ └-┬-┘ └-┬-┘
└---┬---┘ └---┬---┘
└-----------┬-----------┘
A.size
(=4)
内存布局(C顺序,大端序)
┌ ┌----------┬----------┐ ┐ ┐
┌-┤ p+00: │ 00000000 │ 00000000 │ │ │
│ └ ├----------┼----------┤ │ strides[1] │
┌-┤ p+02: │ │ │ │ (=4) │
│ │ ┌ ├----------┼----------┤ ┘ │
│ └-┤ p+04 │ 00000000 │ 00000010 │ │
│ └ ├----------┼----------┤ │ strides[0]
│ p+06: │ │ │ │ (=12)
│ ├----------┼----------┤ │
A.nbytes -┤ p+08: │ │ │ │
(=8) │ ├----------┼----------┤ │
│ p+10: │ │ │ │
│ ┌ ├----------┼----------┤ ┘
│ ┌-┤ p+12: │ 00000000 │ 00000110 │
│ │ └ ├----------┼----------┤
└-┤ p+14: │ │ │
│ ┌ ├----------┼----------┤
└-┤ p+16: │ 00000000 │ 00001000 │
└ └----------┴----------┘
└---------------------┘
A.itemsize
A.dtype.itemsize
(=2)
可以直接修改ndarray对象的strides属性,改变ndarray的内存布局,但此时会修改原数组。
A = copy.deepcopy(np.arange(9, dtype=np.int16).reshape(3, 3))
A.strides = (2, 4)
pprint.pprint(A)
array([[0, 2, 4],
[1, 3, 5],
[2, 4, 6]], dtype=int16)
视图和副本
视图和副本是优化数值计算的重要概念。
在 NumPy 中,可以用切片和花式索引(整数数组索引)来索引数据。切片将始终返回视图,而整数数组索引将返回一个副本。这种差异很重要,因为在切片情况下,修改视图会修改原数组,而在整数数组索引情况下则不是这样:
Z = np.zeros(9)
Z_view = Z[:3]
Z_view[...] = 1
print(Z)
[1. 1. 1. 0. 0. 0. 0. 0. 0.]
Z = np.zeros(9)
Z_copy = Z[[0, 1, 2]]
Z_copy[...] = 1
print(Z)
[0. 0. 0. 0. 0. 0. 0. 0. 0.]
因此,如果需要反复用到某个花式索引,最好保留它的副本(特别是如果计算它很复杂)。如果不确定索引的结果是视图还是副本,则可以检查base的结果。如果是None,那么结果就是副本:
Z = np.random.uniform(0, 1, (5, 5))
Z1 = Z[:3, :]
Z2 = Z[[0, 1, 2], :]
print("Z1 is equal to Z2:", np.allclose(Z1, Z2))
print("Z1's view is Z:", Z1.base is Z)
print("Z2's view is Z:", Z2.base is Z)
print("Z2 has no view:", Z2.base is None)
Z1 is equal to Z2: True
Z1's view is Z: True
Z2's view is Z: False
Z2 has no view: True
请注意,一些 Numpy 函数在可能的情况下返回视图 (例如,ravel),而另一些函数总是返回副本 (例如,flatten):
Z = np.zeros((5, 5))
print(Z.ravel().base is Z)
True
print(Z[::2, ::2].ravel().base is Z)
False
print(Z.flatten().base is Z)
False
可以通过ndarray.view()方法,从同一块内存区(储存着numpy数组的内存区)创建不同的dtype数组。即用不同的数值类型查看同一段内存中的二进制数据。它们使用的是同一块内存。 实际上,ndarray.view()方法是创建了一个视图。
A = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
A_view = A.view(np.int32) # A_view 是视图
A_view.flags
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : False
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
如果我们直接修改原始数组的dtype,会达到同样的效果,但此时直接修改原始数组。
A.dtype = np.float32
Caution
通常应避免改变由切片、transposes、fortran排序等定义的数组的dtype 的大小,可能会引发错误,如下:
A = copy.deepcopy(np.arange(9, dtype=np.int16).reshape(3, 3))
try:
A_view = A.view(np.int32)
except ValueError as e:
print("ValueError:", e)
ValueError: When changing to a larger dtype, its size must be a
divisor of the total size in bytes of the last axis of the array.
NumPy 数据类型
NumPy 比 Python 支持更多种类的数值类型。因为 NumPy 是用 C 语言构建的,其基本类型与 C 语言中的基本类型紧密相连。C、Fortran 和其他相关语言的用户都很熟悉这些类型。但对于新手来说,记不住这些 NumPy 的 dtype 也没关系。通常只需要知道所处理的数据的大致类型是整数、浮点数、复数、布尔值、字符串,还是普通的Python对象即可。如果需要控制数据在内存和磁盘中的存储方式(尤其是对大数据集),那就得了解如何控制存储类型。详细信息参考 Data types。
| 类型 | 类型代码 | 说明 |
|---|---|---|
| int8、 uint8 | i1、u1 | 有符号和无符号的8位(1个字节)整型 |
| int16、uint16 | i2、u2 | 有符号和无符号的16位(2个字节)整型 |
| int32、uint32 | i4、u4 | 有符号和无符号的32位(4个字节)整型 |
| int64、uint64 | i8、u8 | 有符号和无符号的64位(8个字节)整型 |
| float16 | f2 | 半精度浮点数 |
| float32 | f4或f | 标准的单精度浮点数。与C的float兼容 |
| float64 | f8或d | 标准的双精度浮点数。与C的double和Python 的float对象兼容 |
| float128 | f16 或 g | 扩展精度浮点数 |
| complex64、complex128、 | c8、 c16、 | 分别用两个32位、64位或128位浮点数表示的 |
| complex256 | c32 | 复数 |
| bool | ? | 存储True和False值的布尔类型 |
| object | O | Python对象类型 |
| string_ | S | 固定长度的字符串类型(每个字符1个字节)。 例如,要创建一个长度为10的字符串,应使用 S10 |
| unicode_ | U | 固定长度的Unicode类型(字节数由平台决定)。 跟字符串的定义方式一样(如U10) |
-
例外:Numpy的结构数组的元素可以不同质。 ↩